This is the story behind Outside Echo's two major projects, LLSTI and Audio Notetaker.
The vision for a purpose-driven technology business
It was in 1992, when I was speaking at Voice Systems London, that I came across how Dragon Dictate was being used by disabled students. I remember staying late for the final session with Dragon instead of getting an early train home because I was amazed to see what a difference a good piece of technology could make to someone’s life. I would have loved to work on a technology like that, but although Dragon Systems did have a lab in the UK which I was familiar with, it was only working on telephone digit recognition. The dictation systems were developed in the US.
I put all this to the back of my mind and in 1994 took a job with HP labs in Bristol. It was there in 2001 that I volunteered for the e-inclusion initiative in HP and worked with other HP volunteers from around the world to brainstorm opportunities that poor communities in the developing world would have if connected to the internet. I was exposed to Prahalad’s “Wealth at the bottom of the Pyramid” and this deeply influenced our whole team as we put together strong cases for HP getting involved with very poor people. I remember being interviewed at the Tomorrow’s World exhibition that year when the reporter asked me “so let me get this right, HP are wanting to make money out of the very poorest people in the world?” The answer was yes and no. It was the first time I’d been exposed to the idea of a business who had a mission to affect people’s lives for the better, but in order to sustain that mission needed to earn revenue in the process. I explained this to the reporter, I don’t know if he really bought it.
LLSTI - incubating speech technology centres in the developing world
Later that year I got invited to go to Bangalore to speak about speech technology localisation and to present some ideas I had put together for a text-free mobile computing device, which in principle at least did not require any literacy to use. As I presented the idea at various places in India I got a fairly luke-warm reaction to the text-free computing idea, but a very good reaction to the idea of text to speech and speech recognition interfaces for conventional computers and voice services.
In 2002 HP set up a research lab in India to focus on technology for the Indian subcontinent and the developing world in general, and I worked with the new labs on the language technology part of their research agenda, as well as developing some technology of my own back in the UK. But later on that year, following on from the HP/Digital/Compaq merger, I found myself redundant, too expensive to be funded by HP India but unsupported by HP UK.
By this time I had become familiar with the world of IT for Development (IT4D) and had understood several problems regarding speech technology for the developing world:
- Speech tech companies showed some interest in the more major languages. But to develop TTS or ASR they would hire a native speaker as temporary consultant, localise their system to that language, and add it to their language list. This did not transfer ownership of that tech to any of the speakers of that language.
- The more minor languages were off the radar for these companies.
- There was in any case some deep problems involved in transferring technology to the developing world. Too many rooms full of PCs were left gathering dust as puzzled community leaders or head teachers didn’t really know what to do with them.
I saw the way forward was for the countries themselves to take responsibility for their own speech technology development and its deployment. But most did not have enough expertise or political backing to do this - they needed a catalyst to get them going.
And so was born the idea of a project that would bring expertise from the worldwide speech tech community to partners from around the developing world who could see the potential of speech and language technology for their country. I successfully sold the idea to both DfID in the UK and IDRC in Canada and received some grant funding to instigate and run the project, the Local Language Speech Technology Initiative (LLSTI). To receive the funding, I needed a not-for-profit organisation, and this is how Outside Echo came into being.
 The object of LLSTI was to incubate centres of SLT expertise around the world, focusing on developing and applying the technology to address information access issues in those countries. Outside Echo - at that time just myself and Dr Ksenia Shalanova - initiated and managed the LLSTI from 2003-2007. This unique global, developing-world, project based on Open Source software ended up producing text-to-speech (TTS) technology in a number of regional languages. Although we never found a way for LLSTI to sustain itself, those initial partners all continued their speech technology development, going on to produce voice-based information systems in Kiswahili and all eleven South African languages. The award-winning Kenyan National Farmers Information Service nafis.go.ke is a good example of one of these.
The object of LLSTI was to incubate centres of SLT expertise around the world, focusing on developing and applying the technology to address information access issues in those countries. Outside Echo - at that time just myself and Dr Ksenia Shalanova - initiated and managed the LLSTI from 2003-2007. This unique global, developing-world, project based on Open Source software ended up producing text-to-speech (TTS) technology in a number of regional languages. Although we never found a way for LLSTI to sustain itself, those initial partners all continued their speech technology development, going on to produce voice-based information systems in Kiswahili and all eleven South African languages. The award-winning Kenyan National Farmers Information Service nafis.go.ke is a good example of one of these.
LLSTI did not become the large global initiative I had hoped it would, a recent assessment of it was that it was simply too early - but it did present a great example of how to do technology transfer to the developing world. The essence is to set the project up for transfer from the very beginning, and not to add it as an afterthought to the end.
You can find out more about LLSTI at the project archive, which also contains a list of LLSTI publications.
Audio Notetaker - multi-media note-taking
During my time running the LLSTI project, something happened to bring my attention to the plight of dyslexics regarding note-taking. Taking comprehensive notes from lectures, interviews and meetings is never easy, but for people with dyslexia, dyspraxia, ADHD and other learning difficulties, it can be almost impossible.
I quickly realised this was another opportunity for the text-free computer interface, which could now be combined with image, text, and colour to provide a set of multi-media notes. But I needed to wait until the LLSTI partners became self-sustaining before I was able to do anything with it.
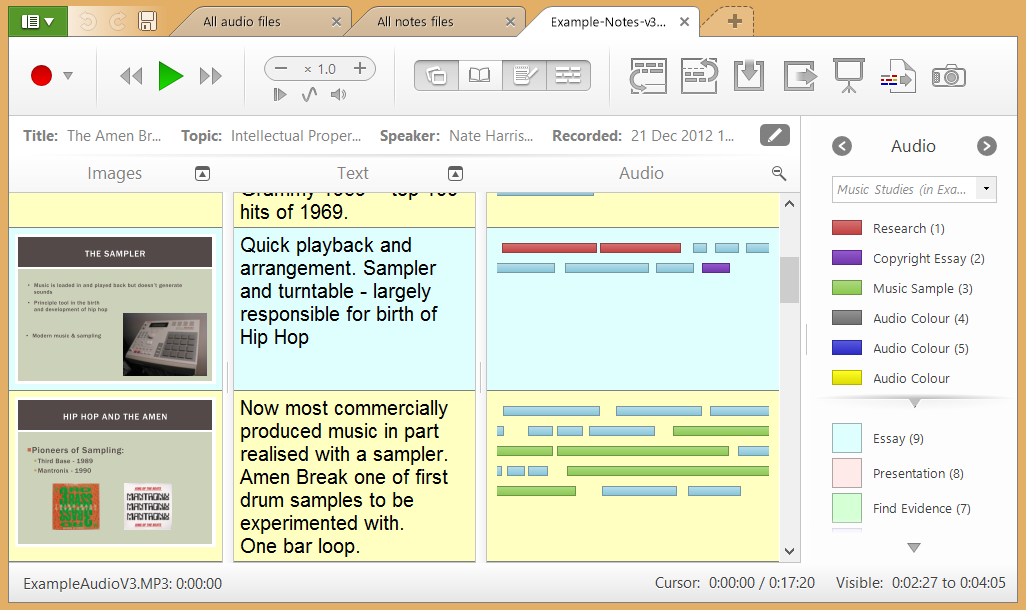
I didn't actually know much about dyslexia - I have no personal experience within my immediate family. Prof Pat Hall (Open University) was also quite interested in the synergy between illiteracy and dyslexia, and put me in touch with Dr Ross Cooper from the Dyslexia Unit at South Bank University in London. They were very excited about the idea and in the summer of 2005 together we arranged focus groups where I was able to test out all the various aspects of an audio note-taker using Powerpoint simulations of how it would work. The focus groups were incredibly positive and I knew then that I needed to push the idea forward. However it was not at all obvious how to do that, and the story of how it all unfolded is quite a long and interesting one, which involved setting up and running a new company, now known as Glean (formerly Sonocent), which occupied me for 10 long years until 2017. I was greatly helped by belonging to the tech business incubator SetSquared in Bristol, and in particular its director Nick Sturge, whose encouragement and insight helped us through many problems as we grew to become the outstanding company that Glean is today.
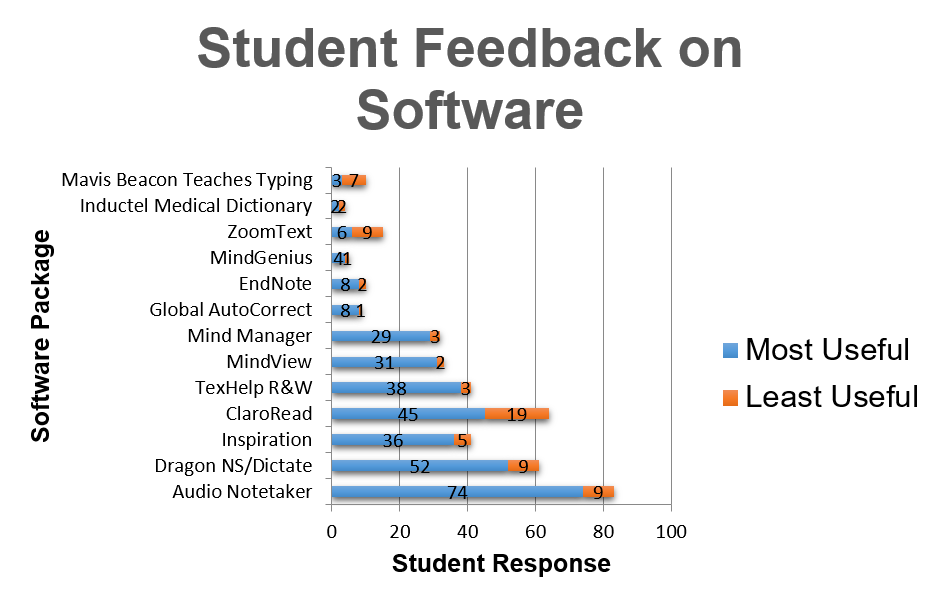
The text-free approach has been very successful, and we have won our fair share of awards over the years. But the highlight for me was in July 2013 when I was taking part in a training day for various assistive technologies in London. One of the other presentations was by David Baxter-Williams of Assistive IT Solutions, a Disabled Student Allowance (DSA) systems integrator and supplier. Before he started on the product he was training on, he put up a slide showing the results of a survey he had sent to all the DSA students he supplied with assistive technology. The assisstive technology I had admired all this time, the speech-to-text app Dragon, was the second most useful - but the most useful of all was Audio Notetaker.
In her recent short book “Leading the Future of Technology” (Cambridge Elements, Dec 2020), Rebecca LaForgia reflects on the significance of the text-free user interface (p22):
What is the inspirational motivation when we look to the artefacts of these coloured blocks of audio? What we see is the representation of sound, information, words, and knowledge not in a written form. We see, through the coloured blocks, literacy before it is born as a word-style symbol. We see literacy and knowledge as a physical block. The information, the knowledge, the words simply look like the rectangular building blocks with which a child might play. The image is inviting and cubist; the blocks are small, long, and of different colours, and they can be arranged.
The inspirational motivation here is that this technological artefact has achieved, for all people who view it, a different representation, a diverse representation of literacy. The artefact shows literacy before it is contained in a word symbol. In this sense, it is an accessible technological artefact that is a symbol of diversity. It provides an artefact of a different way of engaging with knowledge and literacy. It stands functional and proud, symbolically composed of different colours and shapes. The coloured blocks, could potentially educate all who look at them, about the nature of thinking and the diverse relationships that people have with literacy. Looking at the Sonocent coloured blocks, there is no requirement for empathy for the person with dyslexia or diverse thinker.
Empathy is not the lesson here. The coloured blocks are more breathtaking. They are a visual representation of different ways of thinking about literacy – of having a coloured sound block to represent literacy before there is even a hint of the written symbol of a word. I interpret the visual representations of Sonocent as inspiring. Like looking at a work of art by Cézanne, who was said to have introduced into the world of painting a new form that moved from the literal and realist approach to capture a wholly different way of representing the world.
You can find out more about Audio Notetaker at the old Sonocent website and it's successor, Glean, at Glean's website.